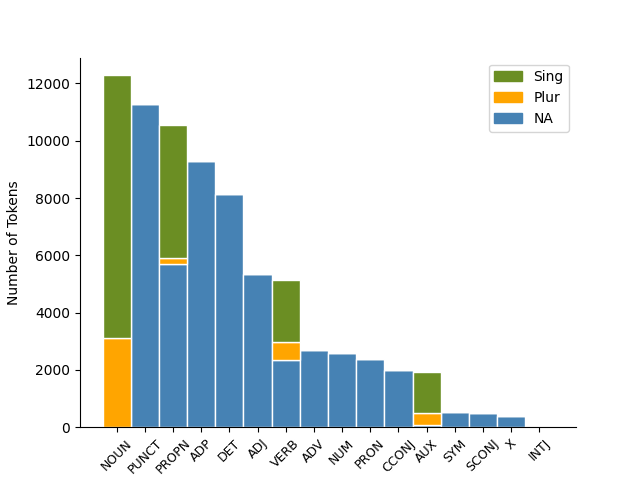
Token Distribution across Number
The following histogram captures the token distribution per different part-of-speech (POS) tags.
Legend on the top-right shows the different values the Number attribute takes.
'NA' denotes those tokens which do not possess the Number attribute.
Token examples for each POS:
Number agreement rules:
The following decision tree visualizes the rules used for classifying presence/absence of morphological agreement between two tokens that are connected by a dependency relation denoted by relation. head-pos and child-pos refer to the POS tag of the head and child token respectively.
Each node of the tree represents a portion of the data. samples denotes the number of training data points in that node. value is the class distribution within that node. Each edge denotes the feature used for splitting.
Leaf nodes contain the description of all of the features that appear in that leaf. * denotes that the feature can take any value.
Tree for p=0.01
Click on to show summary of agreement rules.
- VERB tokens agree when the dependent token belongs to [NOUN] for the dependency relations: subject(subj), unk@fixed(unk@fixed), oblique complements(comp:obl), compound(compound@prt)
- PROPN tokens agree when the dependent token belongs to [PROPN] for the dependency relations: conjunct(conj), flat multiword expression(flat), modifer(mod)
- AUX tokens agree when the dependent token belongs to [NOUN] for the dependency relations: predicative complements(comp:pred), subject(subj@pass)
- All tokens agree with their head tokens for the dependency relations: parataxis (parataxis)
- PROPN tokens agree when the dependent token belongs to [NOUN] for the dependency relations: appositional modifier(appos)
- PROPN tokens agree when the dependent token belongs to [VERB] for the dependency relations: modifer(mod@relcl)
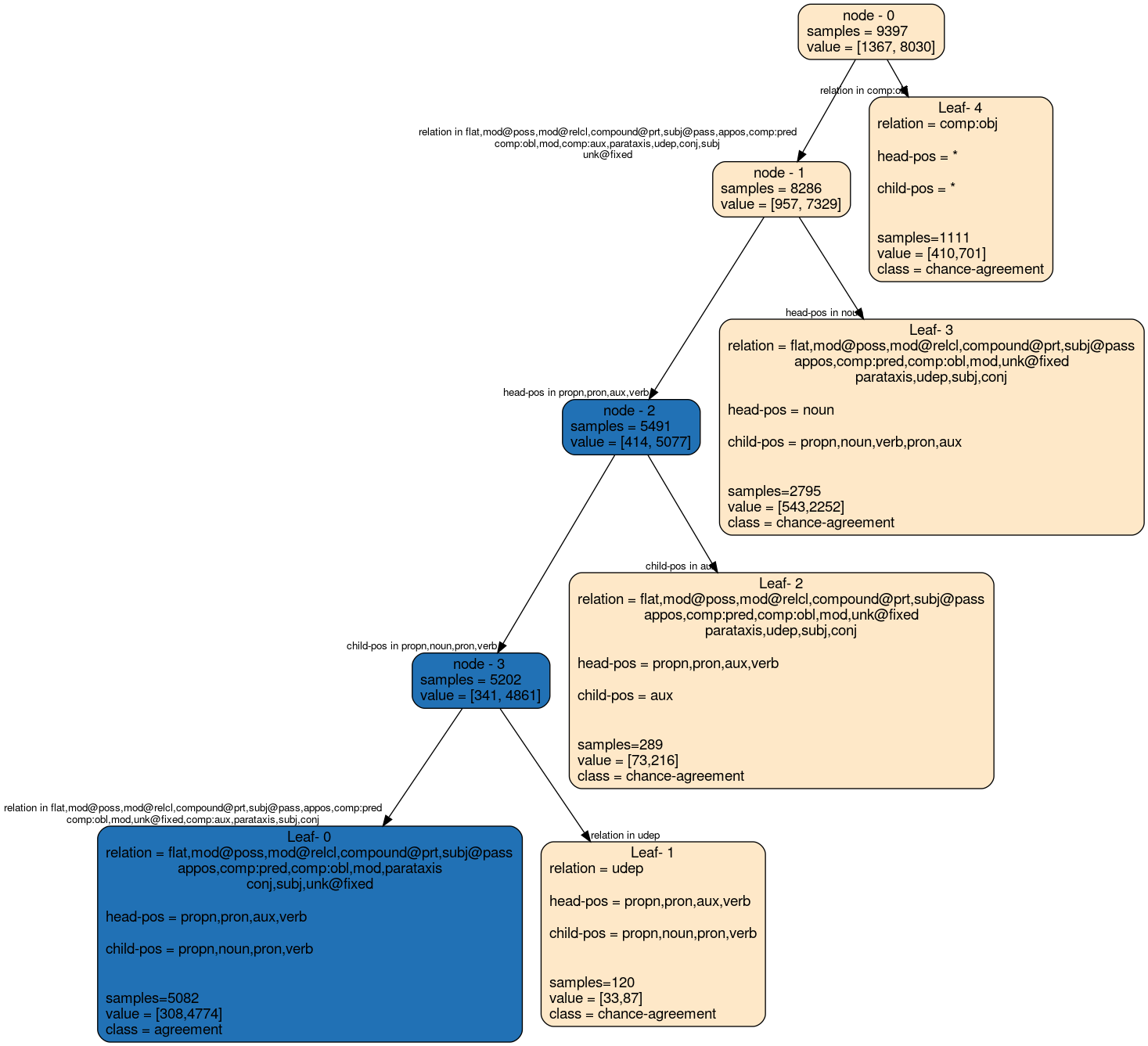
Examples for each leaf node:
Click on to expand the tree.